Fish-Speech 是一个基于先进的深度学习模型,专门用于语音生成和合成的开源项目。它结合了最新的技术,如 GAN(生成对抗网络)和 VQ-VAE(向量量化变分自编码器),在多种语音生成任务中展现了卓越的表现。
对于开发者和研究人员来说,能够在本地部署这些模型并进行定制化训练和调优,是提升应用效果、加速研发的重要途径。然而,由于深度学习模型通常需要高效的计算资源、复杂的依赖库和框架,在本地部署这些模型并不是一件简单的事。本文将详细介绍如何在 Windows 环境中本地部署 Fish-Speech 模型,帮助开发者轻松完成模型的安装、配置以及启动过程。下面我们就看看如何从 0 在本地搭建这个模型。
首先不要运行官方的install_env脚本,我运行完后conda和python环境全乱了,而且最后还报错,跑不起来。只能把conda和python全部重装。还是老老实实手动安装,这里需要使用到conda。先安装miniconda。
官方网站
基础环境
Anaconda Navigator
下载代码
代码和项目里的依赖会比较耗时,确保梯子稳定可用。
git clone https://github.com/fishaudio/fish-speech.git
安装虚拟环境和依赖
在项目根目录下运行以下命令
# 创建一个 python 3.10 虚拟环境, 你也可以用 virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# 安装 pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
# 安装 fish-speech
pip3 install -e .
# (开启编译加速) 安装 triton-windows
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl注意:pip install -e后面有个点。
最后的编译加速可以不安装,加速类的东西容易报错。显示找不到cuda的path,暂未解决。
torch的下载速度非常慢,但是可以把链接复制出去用浏览器或其他下载工具,有科学上网会更快。把下好的whl文件复制到项目目录,执行pip install xxxxxxxx.whl。安装完成后再执行上面安装 pytorch的命令。
如果遇到错误,用管理员打开CMD重试。
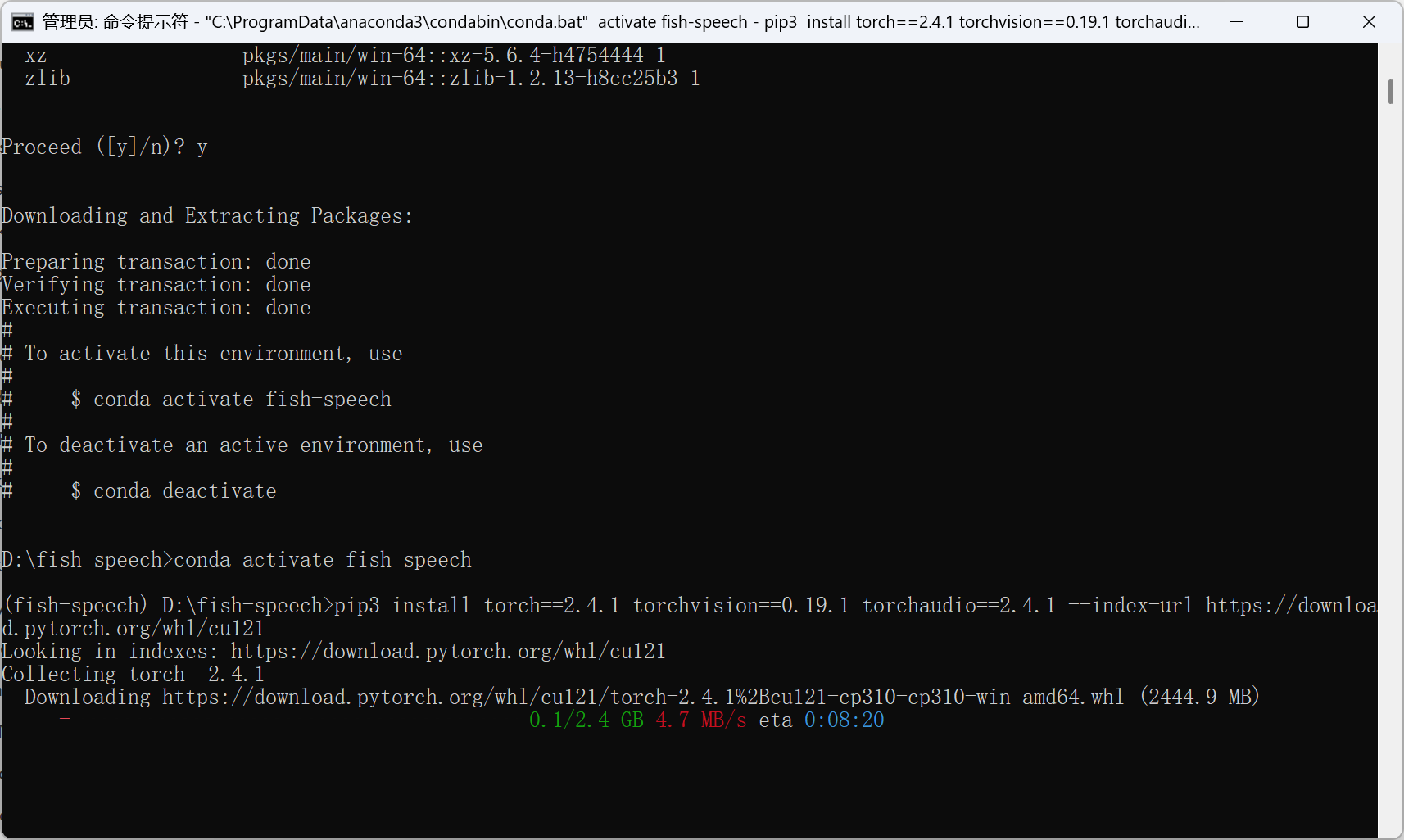
依次安装成功。
准备数据
安装好环境后,处理数据,数据需要wav文件和lab文件,lab文件中是语音对应的文本,wav和lab名字相同。格式类似下面的。mp3,wav等常见格式都支持。
fish-speech
├── data
│ ├── 21.15-26.44.lab
│ ├── 21.15-26.44.mp3
│ ├── 27.51-29.98.lab
│ ├── 27.51-29.98.mp3
│ ├── 30.1-32.71.lab
│ └── 30.1-32.71.mp3在项目下新建一个data文件夹,将wav和lab一起放在这个文件夹。
下载预训练模型:
huggingface-cli download fishaudio/fish-speech-1.5 --local-dir checkpoints/fish-speech-1.5也可以手动去huggingface下载,也可使用git(需要支持大文件),需要科学上网。没有的话,国内下载自行搜索教程。最后新建一个checkpoints文件夹,把模型等文件放进去。后面执行脚本应该也会自动下载模型。目录结构大概这样。
应用项目
提取语义token
python tools/vqgan/extract_vq.py data如果内存不够,就调整一些参数,减少batch-size。
python tools/vqgan/extract_vq.py data --num-workers 1 --batch-size 16打包数据,根据实际情况调整batch-size。
python tools/llama/build_dataset.py --input "data" --output "data/protos" --text-extension .lab --num-workers 16微调模型
运行训练前,需要修改fish_speech/configs/text2semantic_finetune.yaml文件,根据显存修改
num_workers和batch_size,都为1,需要7.8GB左右的显存训练,我的数据集比较大,所以显存消耗多,根据实际情况自己慢慢测试,找到最合适的参数。
data:
_target_: fish_speech.datasets.semantic.SemanticDataModule
train_dataset: ${train_dataset}
val_dataset: ${val_dataset}
num_workers: 1
batch_size: 1
tokenizer: ${tokenizer}
max_length: ${max_length}windows下运行训练
python fish_speech/train.py --config-name text2semantic_finetune project=$project +lora@model.model.lora_config=r_8_alpha_16 trainer.strategy.process_group_backend=gloo合并模型
python tools/llama/merge_lora.py --lora-config r_8_alpha_16 --base-weight checkpoints/fish-speech-1.5 --lora-weight results/$project/checkpoints/step_000006400.ckpt --output checkpoints/fish-speech-1.5-mar7th-lora/step_000006400.ckpt 替换为自己的ckpt文件
推理
启动http api
python -m tools.api_server --listen 0.0.0.0:8080 --llama-checkpoint-path "checkpoints/fish-speech-1.5-mar7th-lora" --decoder-checkpoint-path "checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" --decoder-config-name firefly_gan_vq或者启动webui推理
python -m tools.run_webui --llama-checkpoint-path "checkpoints/fish-speech-1.5-mar7th-lora" --decoder-checkpoint-path "checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" --decoder-config-name firefly_gan_vq修改模型目录为自己的模型目录,--decoder-checkpoint-path "checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"这个是解码器目录,不是融合后模型的pth目录。
以下内容参考为主。
运行项目
直接打开项目文件夹,点击 install_env.bat 安装内置环境。建议在命令窗口中输入文件名运行。
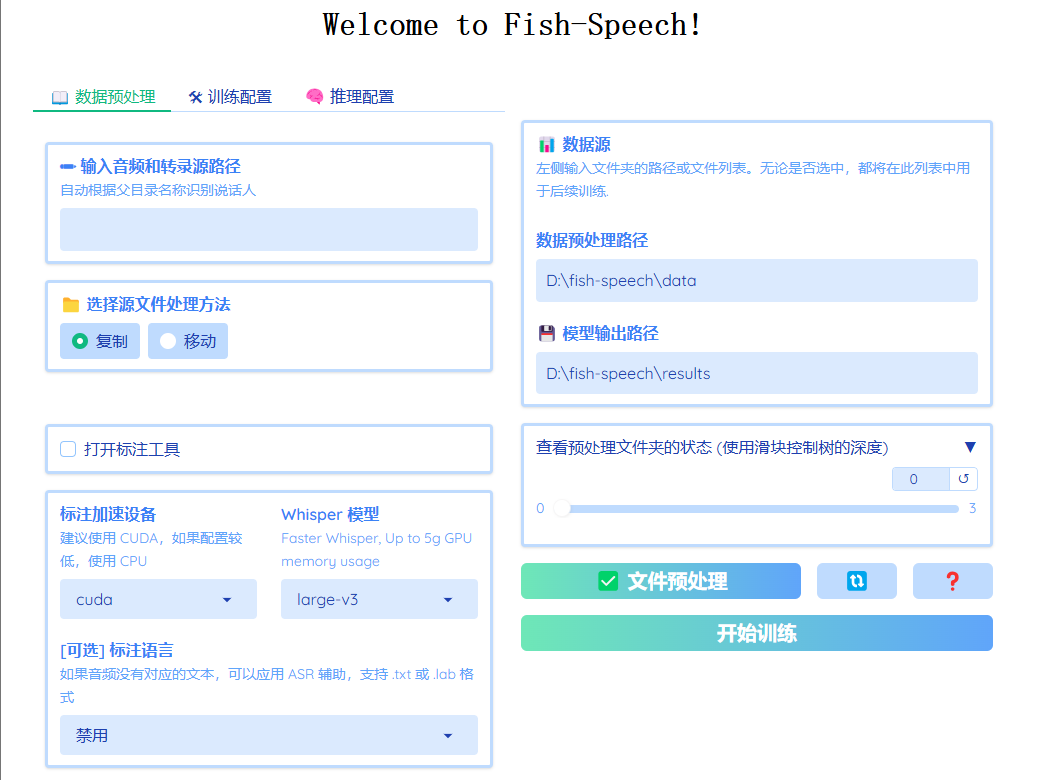
双击start.bat打开训练推理 WebUI 管理界面。在这个过程中会去 Hugging Face 仓库下载模型,确保网络通畅,会出现如下进入。
启动正常,就可以看到下面的页面。那么就可以愉快的玩耍了。